
Operational observability rocks, and so does Fly.io
Do you know what your infrastructure is doing? Not without good telemetry, you don't... Here's why an ops dashboard is so awesome.
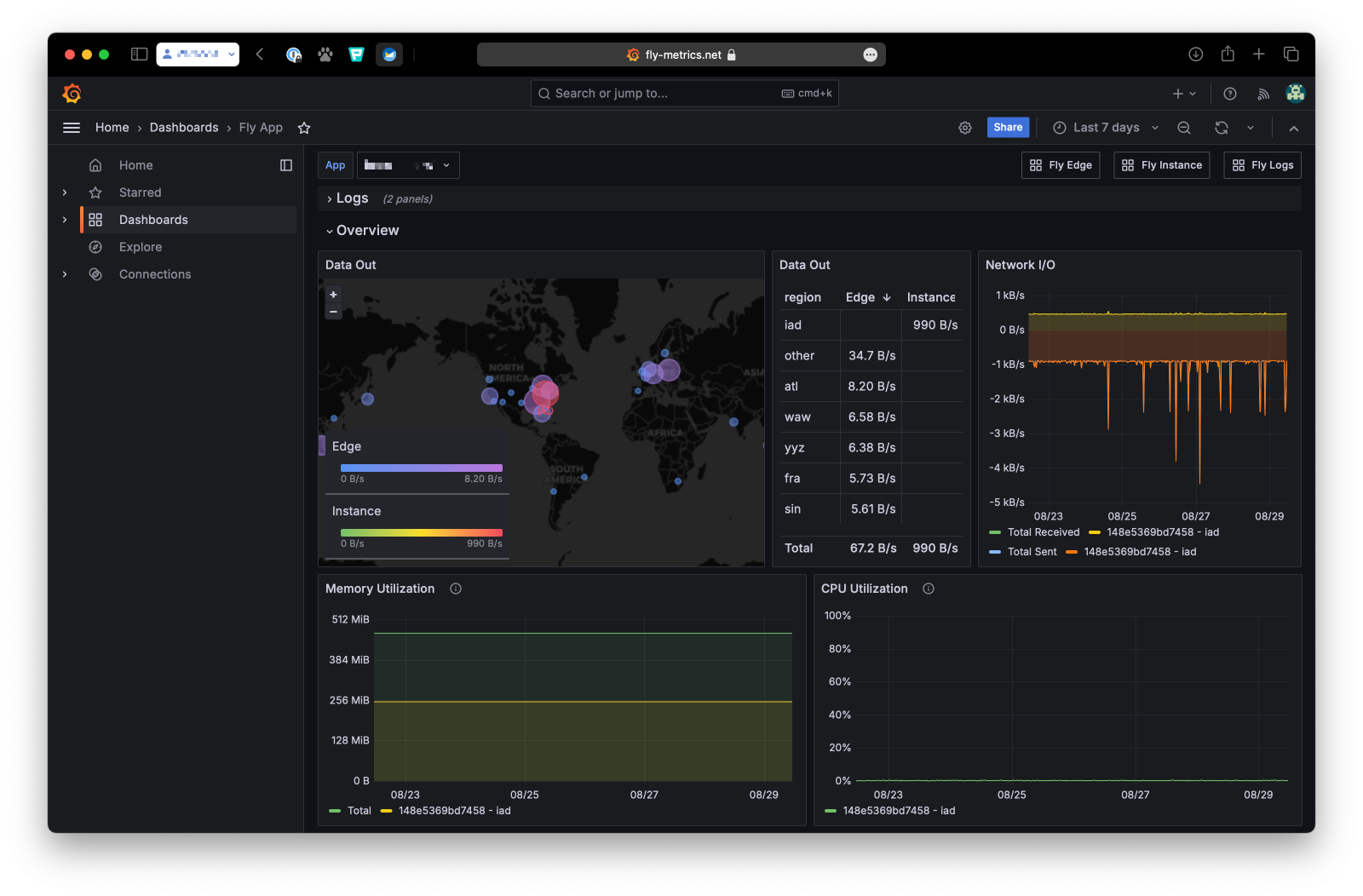
Having fantastic observability metrics is a game changer. The problem is, too many teams think about building telemetry as an add-on, something to do later, once the system is up and running.
That’s totally backwards.
If you’re new, welcome to Customer Obsessed Engineering! Every week I publish a new article, direct to your mailbox if you’re a subscriber. As a free subscriber you can read about half of every article, plus all of my free articles.
Anytime you'd like to read more, you can upgrade to a paid subscription.
Having great telemetry right from the start completely changes your approach to development. It gives you fantastic tools to explore unexpected problems, diagnosis root causes, and expose situations you wouldn't even be aware of until it’s too late. Like, in production, with customers groaning about an unusable web site.
Here’s a case in point. I love this story Fly.io just published in their late…
