
Taking time to plan is not slowing down
Engineers love building things so much it’s often hard to slow down and take the time to plan. But here’s the thing: without the right effort up-front during design, it will always take longer.

I keep being reminded of the Tortoise and the Hare. Aesop’s fable, you know the one?When the Tortoise and Hare race — and the Hare runs ahead, but gets distracted and decides to nap until the Tortoise catches up. Meanwhile the Tortoise keeps going slowly but steadily, and, after a time, passes the Hare, who sleeps on very peacefully; and when at last he did wake up, the Tortoise is near the goal. The Hare now ran his swiftest, but couldn’t overtake the Tortoise in time.
And this just keeps popping up in my daily life.
If you’re new, welcome to Customer Obsessed Engineering! Every week I publish a new article, direct to your mailbox if you’re a subscriber. As a free subscriber you can read about half of every article, plus all of my free articles.
Anytime you'd like to read more, you can upgrade to a paid subscription.
Moving too fast
Let’s call the DevOps engineer Carl. He’s energetic, smart, and ready to dive in — which he does with gusto. The problem is, every time we talk to Carl about what the customer wants, he immediately translates it into technical terms and starts coding.
me: As a product owner, I want to get an alert if our system starts to slow down, so that I can be aware of potential problems before they become severe.
Carl: Got it. We can use CloudWatch to send an email if server CPU or memory usage gets too high. And AWS Lambda timeouts to send an email if an endpoint is taking too long.
There’s a problem with going straight to the technology.
By translating what the customer wants into a technical objective, the original goal is lost. The goal becomes “set up CloudWatch and Lambda alerts.” That’s not what the customer asked for.
The customer wants to know “if the system starts to slow down.” That is the one thing we have to rally around, and it’s not just CPU, memory, and endpoint monitoring. We can’t possibly know everything that would cause the system to slow down — because the system changes, evolves, and develops over time. New feature are added, new discoveries are made.
So the best possible thing we can do is make “send an alert when the system gets slow” our core feature, and make it a part of our requirements without changing that simple language the customer used to describe it.
Fail fast, correct quickly
Our customer also wants an AWS environment that doesn’t slow the team down, and doesn’t spin out of control. One feature was, “as a developer, I want to be able to start or stop resources, so I can develop code without being slowed down.” A complimentary one was, “as a product owner, I want the production environment to be entirely automated, and I want to review apps before they go live, so production is safe.”
There’s a tremendous amount of complexity in these simple statements. You have to set up landing zones for different roles, making sure developers have relative freedom, while also putting in place cost controls. An entire CI/CD pipeline is needed to handle SAST, DAST, build, deployment. We need full automation to protect production, which means Infrastructure as Code at every step. And this is just the tip of the iceberg.
When it came time to deliver, Carl read the features, said they were clear, and knew how to build it. We lined up a sprint, and the team was off and running.
Carl started building out infrastructure using the AWS dashboard — which meant, everything has hand-configured, no Infrastructure as Code. Organizations, roles, and users were not set up correctly; instead, we where heading toward a very complicated way of granting permissions at the individual user level (and again, all done using the AWS console).
Yes, it would have worked. It also would have become a nightmare to manage, been prone to human error and taken a lot of manual oversight. It also would have been limited and rigid, because the original intent was lost.
Starting over (slowing down)
We had to reset, go back to the drawing board, do some design work. We took a few days to map out all of the features using event storming — turning each feature into a user journey. Those were translated into behavior driven specifications. Each specification lined up cleanly with specific stories in Jira, and very detailed test criteria. Criteria that specified important details.
We now had a high level AWS architecture diagram, everything was being built using Terraform, creating an entirely automated pipeline, and configuration was managed as part of the code base.
In other words, we treated the pipeline and deployment environment like it was a product. We designed it, and we kept our customer’s goals front-and-center.
It did seem to slow things down.
Sure, it took a few days of doing event maps and writing specifications, and we weren’t writing code during that time. But it aligned the team on what needed to be done — it created a roadmap, clear specifications, and criteria for success (in the form of acceptance tests).
And speeding up
Having taken the time to plan our roadmap, execution largely became a breeze. With clear specifications and the benefit of enough technical architecture, the team is able to move forward at a steady pace. The unknown becomes predictable.
Now the team could effectively deliver a working product. Clear specifications eliminated ambiguity, and alignment around behavior driven specifications that still used our customer’s original language made that possible. Keeping our eye on the original goal, we developed a more comprehensive solution.
It met customer expectations, and it kept everyone’s eye on the ball — in this case, highlighting the need for an underlying telemetry solution that could be easily tapped into. That solution made it possible to monitor and respond to any future event that connects to the telemetry backplane.
The true cost of defects
The true cost correcting our course and delivering what the customer wanted was pretty high. Most of a sprint was wasted on building the wrong thing — and that led to compensating actions. Bringing in more senior team members to do rapid design work, and get things back on track, for instance. But, it certainly could have been a lot worse.
The cost of correcting defects in software has been written about for decades. The first time I saw the Relative Cost to Correct Error diagram, I was in college.1
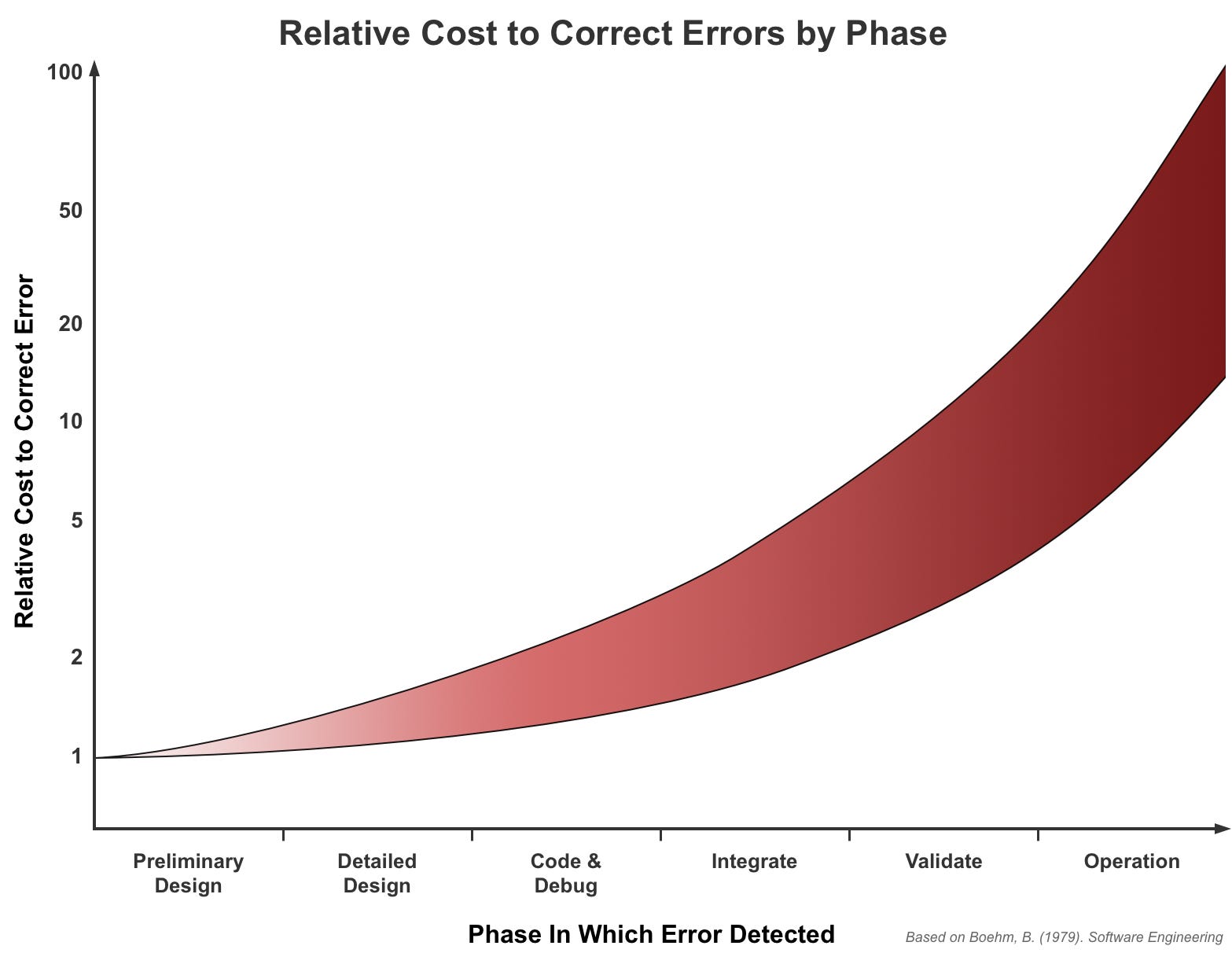
The bottom line is simple: If you catch a defect early, say in design or the first stage of coding, cost is minimal. Programmers create and correct dozens of defects in the routine writing of new code. The trick is to make sure those defects never make it into the pipeline.
Correcting the defect later can be very costly. After a defect is in staging, or worse production, we’re likely looking at days or even weeks to correct the defect and re-release. That’s a lot of wasted effort.
Modern methods quantify “cost” in terms of time or even dollars (such as this Arcad Software diagram that shows a $25 fix in coding growing to $16,000 in production). The Project Management Institute provides a good synopsis (and some handy charts for comparison).
Slow and steady wins the race
The moral of our story — Aesop was right. Take the time to plan. It might seem like you’re slowing down, but it’s that methodical approach that wins the race. It might feel like it will take more time, but it won’t. You’re speeding up.
Further reading

Software Engineering, Randall W. Jensen and Charles C. Tonies, Prentice-Hall (January 1, 1979), ISBN-13: 978-0138221300.
Just saw a perfectly complimentary post by Basma Taha... if you liked "Taking time to plan is not slowing down," check it out! "Writing code? STOP! Think first..." – Lots of parallels but Basma gives some great practical advice on exactly what to do instead of jumping in feet first. → https://bit.ly/3SWagLr